




Code reusability, abstraction, modularity, and ease of debugging are fundamental principles in software development, and Python's functions play a vital role in upholding these principles. By encapsulating specific tasks within functions, developers can create cleaner, more maintainable code. Additionally, introducing testing to the codebase can ensure that the code works as expected. Moreover, Python's functional programming features, such as immutability and parallelization, make it a natural fit for functional programming practices.
PySpark is a framework that extends the Python programming language to work with large-scale data processing tasks on distributed systems. While PySpark inherits many features from Python, it introduces its own set of constructs and approaches for writing reusable code.
In this blog, we will explore various techniques for creating better reusable components within the PySpark ecosystem. We will delve into tips for writing PySpark functions, user-defined functions (UDFs), and discuss the usage of Pandas UDFs.
PySpark Fundamental
Let's talk about the objects in PySpark. When working with the high-level DataFrame API, instead of the lower-level RDD, it's essential to understand the different types of objects involved. These include pyspark.sql.Column, pyspark.sql.DataFrame, pandas.DataFrame, and pandas.Series.
The pyspark.sql.functions module provides a rich set of functions for working with DataFrame columns and data. Depending on the function, you may have the option to pass either a string representing the column name or a pyspark.sql.Column object itself as an argument. To determine which option a particular function supports, it's essential to consult the documentation carefully.
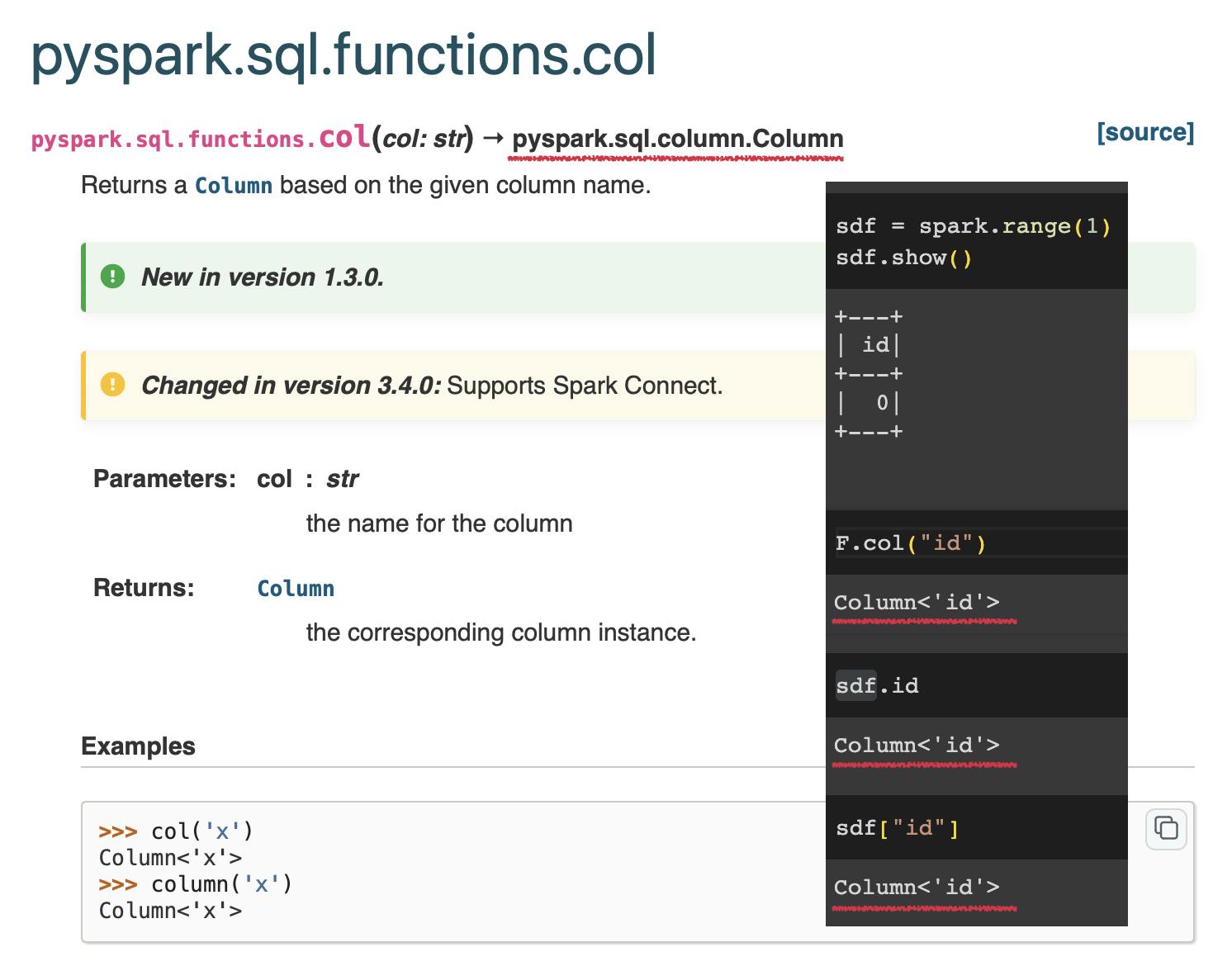
For example, in the documentation, if you see an arrow pointing to pyspark.sql.column.Column, it indicates that the function returns a Column object.
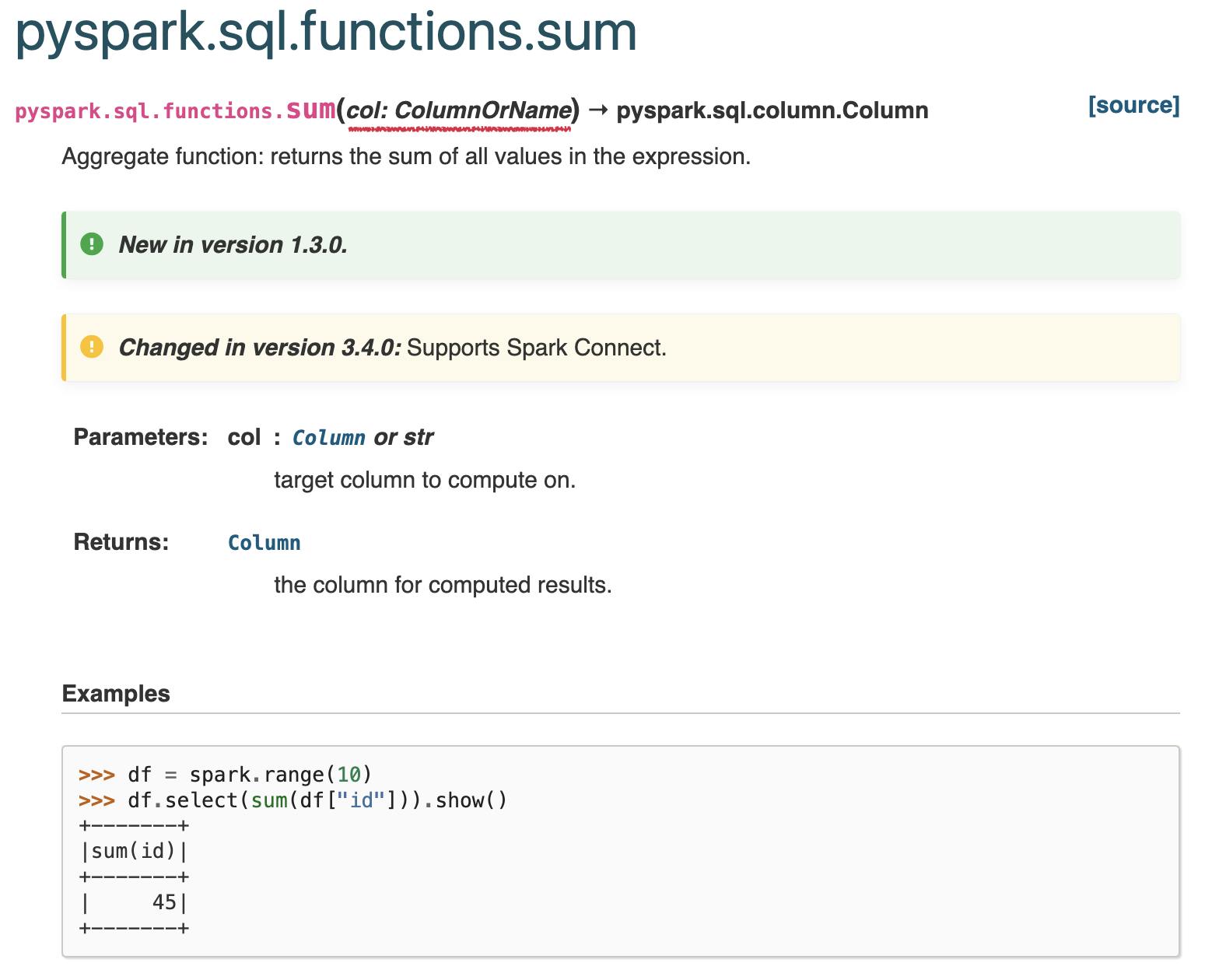
Some functions allow you to pass the column name as an input argument directly. You can identify this by examining the type hints provided in the documentation.
Understanding these fundamental objects and their interplay is crucial for effectively working with PySpark and leveraging its powerful data processing capabilities.
Build your own custom function for Column Transformation
One of the guiding principles I keep in mind when creating PySpark functions is to ensure that the input and output types are the same/similar. This allows for chaining multiple functions together to build more complex operations. There are three primary ways to write custom column functions: Native PySpark, Pandas UDF, and Python UDF, with Native PySpark being the preferred approach, followed by Pandas UDF and Python UDF.
Suppose we have a DataFrame column like this:
spark.range(5).show()
"""
+---+
| id|
+---+
| 0|
| 1|
| 2|
| 3|
| 4|
+---+
"""
Native PySpark Function
Let's write a function to add 1 to each value in this column using the Native PySpark approach:
def plus_one(col_name: "ColumnOrName") -> pyspark.sql.Column:
# Enabled to type string as the input parameter
output_col = col_name if isinstance(col_name, pyspark.sql.Column) else F.col(col_name)
print(type(output_col))
# Actual Logic
return output_col + 1
spark.range(5).select(
F.col("id") + 1,
plus_one(F.lit(0)),
plus_one("id"),
plus_one(F.col("id")),
plus_one(plus_one(F.col("id"))),
).show()
"""
<class 'pyspark.sql.column.Column'>
...
+--------+-------+--------+--------+--------------+
|(id + 1)|(0 + 1)|(id + 1)|(id + 1)|((id + 1) + 1)|
+--------+-------+--------+--------+--------------+
| 1| 1| 1| 1| 2|
| 2| 1| 2| 2| 3|
| 3| 1| 3| 3| 4|
| 4| 1| 4| 4| 5|
| 5| 1| 5| 5| 6|
+--------+-------+--------+--------+--------------+
"""
With the plus_one function, we are directly working with the PySpark Column object, which allows us to perform operations like addition. You can leverage all the functions and column utilities provided by PySpark to help you write your logic.
Pandas UDF
However, if you need a custom logic that is not available in the native PySpark API, you can try using a Pandas UDF instead. Pandas UDFs leverage the power of the Pandas library to process data. With Pandas 2.0, it utilizes Apache Arrow, which enables efficient data transfer to the Pandas system. Additionally, using Pandas allows you to take advantage of its vectorization capabilities, potentially making the process faster. The input to a Pandas UDF will be a Pandas Series or a Pandas DataFrame, depending on what you pass in. This approach is similar to writing native Pandas transformations, and you can use the apply method to run custom functions.
Here's an example of a Pandas UDF:
@F.pandas_udf(T.IntegerType())
def plus_one_pudf(val_ps: pd.Series) -> pd.Series:
return val_ps + 1
@F.pandas_udf(T.StringType())
def print_type_pudf(val_ps: pd.Series) -> pd.Series:
return val_ps.apply(lambda x: str(type(x)) + str(type(val_ps)))
spark.range(5).select(
plus_one_pudf(F.lit(0)),
plus_one_pudf("id"),
plus_one_pudf(F.col("id")),
print_type_pudf(F.lit(0)),
).show(truncate=False)
"""
+----------------+-----------------+-----------------+--------------------------------+------------------------------------------------+
|plus_one_pudf(0)|plus_one_pudf(id)|plus_one_pudf(id)|plus_one_pudf(plus_one_pudf(id))|print_type_pudf(0) |
+----------------+-----------------+-----------------+--------------------------------+------------------------------------------------+
|1 |1 |1 |2 |<class 'int'><class 'pandas.core.series.Series'>|
|1 |2 |2 |3 |<class 'int'><class 'pandas.core.series.Series'>|
|1 |3 |3 |4 |<class 'int'><class 'pandas.core.series.Series'>|
|1 |4 |4 |5 |<class 'int'><class 'pandas.core.series.Series'>|
|1 |5 |5 |6 |<class 'int'><class 'pandas.core.series.Series'>|
+----------------+-----------------+-----------------+--------------------------------+------------------------------------------------+
"""
Python UDF
The least performant option would be using a vanilla Python UDF. You could still enable Arrow in the decorator do get a better performance. When writing a Python UDF, you should think of it at a single data level, where the function takes a single value from the column, and you perform the transformation on that value.
@F.udf(T.IntegerType(), useArrow=True)
def plus_one_udf(val: int) -> int:
return val + 1
@F.udf(T.StringType())
def print_type_udf(val: int) -> str:
return str(type(val))
spark.range(5).select(
plus_one_udf(F.lit(0)),
plus_one_udf("id"),
plus_one_udf(F.col("id")),
plus_one_udf(plus_one_udf(F.col("id"))),
print_type_udf(F.lit(0)),
print_type_udf("id"),
print_type_udf(F.col("id")),
).show(truncate=False)
"""
+---------------+----------------+----------------+------------------------------+-----------------+------------------+------------------+
|plus_one_udf(0)|plus_one_udf(id)|plus_one_udf(id)|plus_one_udf(plus_one_udf(id))|print_type_udf(0)|print_type_udf(id)|print_type_udf(id)|
+---------------+----------------+----------------+------------------------------+-----------------+------------------+------------------+
|1 |1 |1 |2 |<class 'int'> |<class 'int'> |<class 'int'> |
|1 |2 |2 |3 |<class 'int'> |<class 'int'> |<class 'int'> |
|1 |3 |3 |4 |<class 'int'> |<class 'int'> |<class 'int'> |
|1 |4 |4 |5 |<class 'int'> |<class 'int'> |<class 'int'> |
|1 |5 |5 |6 |<class 'int'> |<class 'int'> |<class 'int'> |
+---------------+----------------+----------------+------------------------------+-----------------+------------------+------------------+
"""
Although plus_one_udf, plus_one_pudf, and plus_one look similar, it is crucial to understand the differences and the logic behind these three methods.
Writing functions for DataFrame Transformation
In addition to writing custom functions for column transformations, you can also create functions to perform transformations on an entire DataFrame. This is particularly useful when you want to group a series of transformations into meaningful stages or pipelines.
Here's an example of a function that selects a transformed column from a DataFrame:
def select_plus_one(sdf:pyspark.sql.DataFrame) -> pyspark.sql.DataFrame:
return sdf.select(
F.col("id") + 1
)
select_plus_one(spark.range(5)).show()
spark.range(5).transform(select_plus_one).show()
"""
+--------+
|(id + 1)|
+--------+
| 1|
| 2|
| 3|
| 4|
| 5|
+--------+
"""
This select_plus_one function takes a DataFrame as input and returns a new DataFrame with a single column that adds 1 to the "id" column. You can either call the function directly by passing a DataFrame as an argument, or you can chain the function using the transform method on an existing DataFrame.
By encapsulating these transformations into reusable functions, you can improve the modularity and readability of your code. It also allows you to easily compose more complex transformations by combining multiple functions together.
You might want to group these transformations into meaningful stages or pipelines. For example, you could have separate functions for data cleaning, feature engineering, and model preparation stages, each building upon the output of the previous stage.
By adopting this modular and functional approach, your code becomes more maintainable, testable, and easier to reason about, which is particularly important when working with large and complex data processing pipelines.
pyspark.sql.DataFrame.transform — PySpark master documentation (apache.org)
Next Step
To further understand functional programming principles and best practices for data engineering, I highly recommend exploring the blog posts by Stephen David Williams. He does an excellent job of explaining the SOLID principles for Spark applications and discussing functional programming concepts in the context of Python and data engineering.
Some relevant posts from his blog include:
These resources provide valuable insights into writing modular, maintainable, and testable code for data engineering projects, while leveraging functional programming concepts in Python.
If you have any questions or feedback, feel free to leave a comment below or send me a message on LinkedIn! 📩. Happy coding! 😊
![]()